During university, in particular in the course of Advanced Programming for Scientific Computing – when I developed this small project –, I used to study from my notes and from books or slides in pdf. However, I often found pdf resources to be quite dispersive; in particular, two were the most common problems: sometimes there were 20 or more individual files for a single course, and sometimes there was no clickable index. For the second problem I also kind of developed a solution which scans the index, identifying titles and pages assignments, and automatically creates clickable links, visible from a normal pdf viewer as in pdfs produced by LaTeX, to the corresponding sections. However, this project focuses on the first problem, which I solved by developing a small bash tool which combines multiple pdfs into a single and tidy document which also condenses (and appropriately shifts) all the tables of contents of each pdf. In other words, the script combines each input pdf into the final document while also introducing a global table of contents where the name of each input pdf becomes a Section, and the corresponding sections of each input file become Subsections of the newly introduced Section in the final file.
Github repository: https://github.com/federicomor/merge-pdf-with-toc.
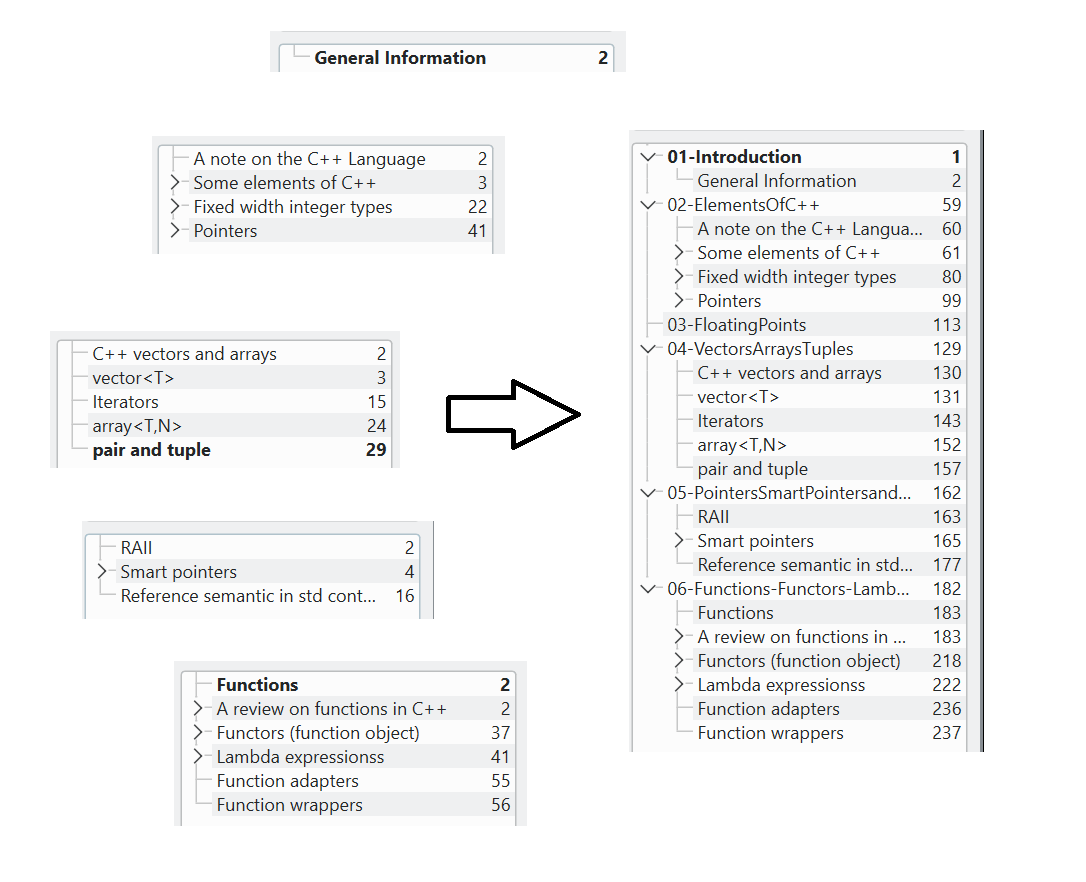
representation of what the script does
